The Is Similar filter uses the Levenshtein Distance, which measures the string metric difference of two sequences. The Levenshtein Distance basically measures the effort needed to transform one text into another.
In other words:
The Is Similar filter measures (in percentage) how many letters two texts are apart from each other.
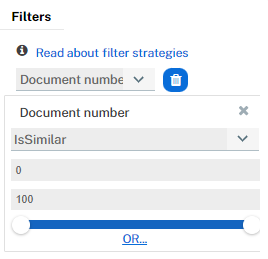
The Is Similar filter is not applicable to every field. This filter works especially well on free-form texts like for example:
- Document number
- Vendor name
- Posting text
- Item text of all non-empty line items in debit
- and more...
The measurement of similarity is done in percent.
The following example shows the result of setting the desired similarity of the "item text" field from 90% - 99%. As shown in this case, the contained text differs only by one digit.

In contrast, this second example shows a similarity between two entries of 50%-60%. Although the strings are differing from each other a lot more than in the 99% example, the information given by the text is identical.

Advanced Strategies with the Is Similar function
The property of the IsSimilar filter can be used especially well in combination with other,
non free-text fields using the AND filter as well.
-png.png?width=228&height=374&name=MicrosoftTeams-image%20(11)-png.png)
A possible advanced strategie would be an examination of duplicate vendors:
You could search for duplicate entries with the following filter settings to find vendors in your system with different ID's but highly similar names.
- Vendor ID - Unequals
- AND-filter
- Vendor name - Is Similar 90%-100%