Sampling and search strategies for zapCash
The AI learns by all your judgments findings. There are many strategies to look at the zapCash data analysis results. Here are the best ones:
We recommend you judge all document pairs with a score above Score 50 first. Furthermore, try to evaluate as heterogeneously as possible to increase the effectiveness of our AI. To do so, you should stick to the following strategy.
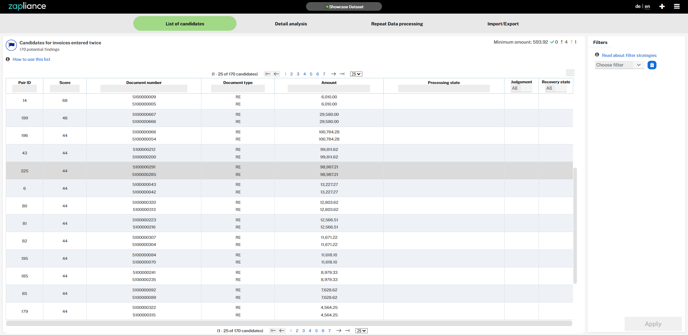
Fig. 1 - Project List of candidates zapCash Version 1.1.0
Sort by Score and Amount
We recommend always going through the top pairs initially and after each AI run. Switch to the following strategy when you can't find more duplicate payments.
Scores from 50 to 100 have a very high probability (%) to be a duplicate payment and should therefore be considered for judgement. You can also sort the "Amount" in descending order to show the pairs with the highest values at the top!
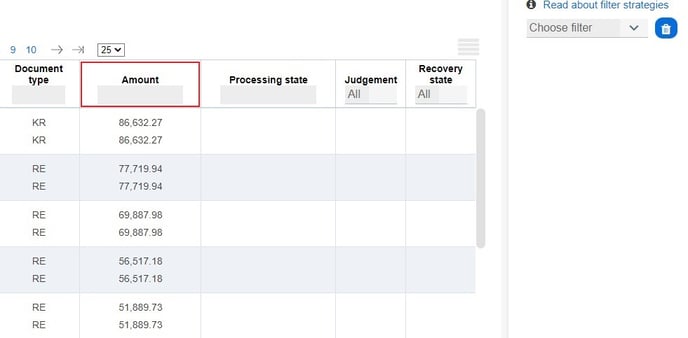
Fig. 2 - "Amount" column sorted in descending order
By Cluster (show/hide columns)
All document pairs are clustered in up to different buckets. The number of clusters depends on the size and complexity of the data set. Usually, there are at least 5 to 20 different clusters. Filter each cluster and investigate at least a couple of pairs. This ensures that the AI considers a wide range of data.
Note that a cluster may be empty, and filtering can give you an empty list!
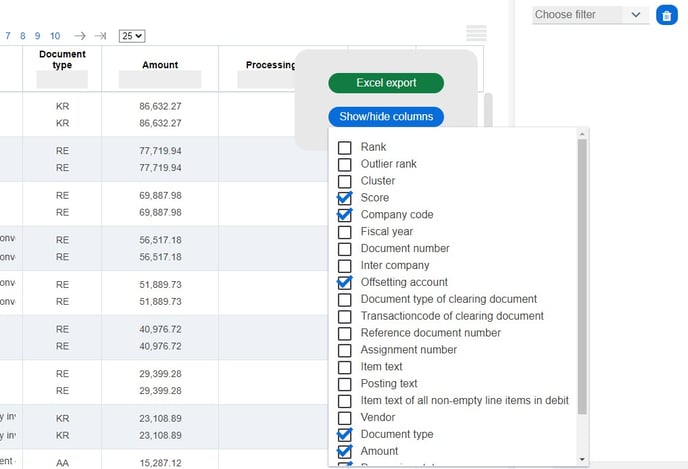
Fig. 2 - Show and Hide Columns zapCash
By Outlier rank (show/hide columns)
zapCash calculates for each document pair how it differs from other pairs. Consider sorting by the Outlier rank to find the most curious cases. This technique is particularly good so that the AI can assess exceptions better.
Outlier rank 1 is the most unusual pair.
Advanced strategies
After using the starter strategies, you may dig more in-depth with the following techniques.
Using the filter to get a more in-depth overview
You may already have some hypotheses about your organization and know-how about duplicate payments that have occurred in the past. For example, invoices may have been sent to the parent company and a subsidiary. You can find such cases by filtering the pairs for unequal company codes.
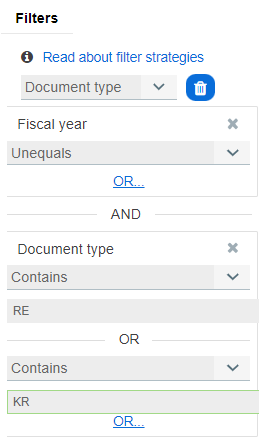
To do so, go to the filter tab. Select one or more items to filter on:
- Company code
- Fiscal year
- Document type
- Assignment or reference number
- Reference transaction
- Inter-company
- Currency
- Vendor ID or name
- and more...
As you always look at pairs of two documents, you can set the filter to one of four filter options:
- Equals: Show only pairs, where the fiscal year of both documents is the same.
- Unequal: Show only pairs, where the fiscal year of both documents is not the same.
- Contains: Show only pairs, where at least one of the two documents contains the free input text. (Case insensitive)
- Not contains: Show only pairs, where at least one of the two documents does not contain the free input text. (Case insensitive)
- One_Empty: Show only pairs, where one position is empty.
- Both_Empty: Show pairs, where both positions are empty.
- None_Empty: Show pairs, where both positions are NOT empty.
- IsSimiliar: Shows pairs that are NOT AT ALL similar to VERY similar in text position (click here for more information on this feature)
You can also connect filters with logical OR and AND.
As we stated initially, it is advisable to evaluate a very heterogeneous sample. Therefore you will find some pairs with score = Q after an import.
We recommend examining those to maximize your findings in the next run.